
벌써 GPT API를 처음 사용해본 이후로 1년반이 지났다. 처음엔 GPT 3.5를 사용했었는데, GPT 4, 4o, 4.5까지 꾸준히 모델이 업데이트 되고 발전되고 있다.
이번 포스팅에서는 GPT API 더 효율적으로 사용하는 방법에 대해서 정리해볼 것이다!
이번 내용은 우아콘 2024 - Fine-Tuning 없이, 프롬프트 엔지니어링으로 메뉴 이미지 검수하기에서 들은 발표 내용을 바탕으로 정리해보았다.
다 아는 내용일 수도 있지만..! 모르는 사람도 있을거라 생각하고.. 정리해보겠다~
(기본 사용법도 소개하려고 했으나 이미 자료가 많고 대부분은 써봤을거라 생각하기 때문에 생략!)
1. System 부분 활용하기
role에는 assistant, user, system을 설정할 수 있다
- system: 모델의 성격, 응답을 정의할 수 있음
- user: 사용자 부분. 질문을 남기거나 명령을 할 수 있음
- assistant: AI 역할. AI의 이전 대화를 첨부하여 이전 맥락을 유지할 수 있음
const messages = [
{ role: "user", content: "GPT를 효과적으로 쓰는 법 알려줘." },
{ role: "assistant", content: "질문을 구체적으로 하면 더 좋은 답변을 받을 수 있어요!" },
{ role: "user", content: "구체적인 질문의 예시를 들어줄 수 있어?" }
];
const response = await openai.createChatCompletion({
model: "gpt-4",
messages: messages
});
나는 평소에 위 예제처럼 user, assistant부분만 활용했었는데, system 부분을 활용하면 처음에 내가 원하는 스타일을 지정해서 일관성있는 답변스타일을 응답받을 수 있다
const messages = [
{ role: "system", content: "너는 친절한 AI 비서야." }, // system 부분 추가
{ role: "user", content: "GPT를 효과적으로 쓰는 법 알려줘." },
{ role: "assistant", content: "질문을 구체적으로 하면 더 좋은 답변을 받을 수 있어요!" },
{ role: "user", content: "구체적인 질문의 예시를 들어줄 수 있어?" }
];
const response = await openai.createChatCompletion({
model: "gpt-4",
messages: messages
});
특히 json으로 응답 받을 때!! 유용하다
이거 몰랐을 때는 프롬프트에 "json으로 응답해줘"를 매번 붙였었는데, json이 안 올 때도 있어서 오류가 종종 있었다.
{ "role": "system", "content": "너는 JSON 형식으로 응답해야 해. 모든 답변을 JSON 형태로 작성해줘." }
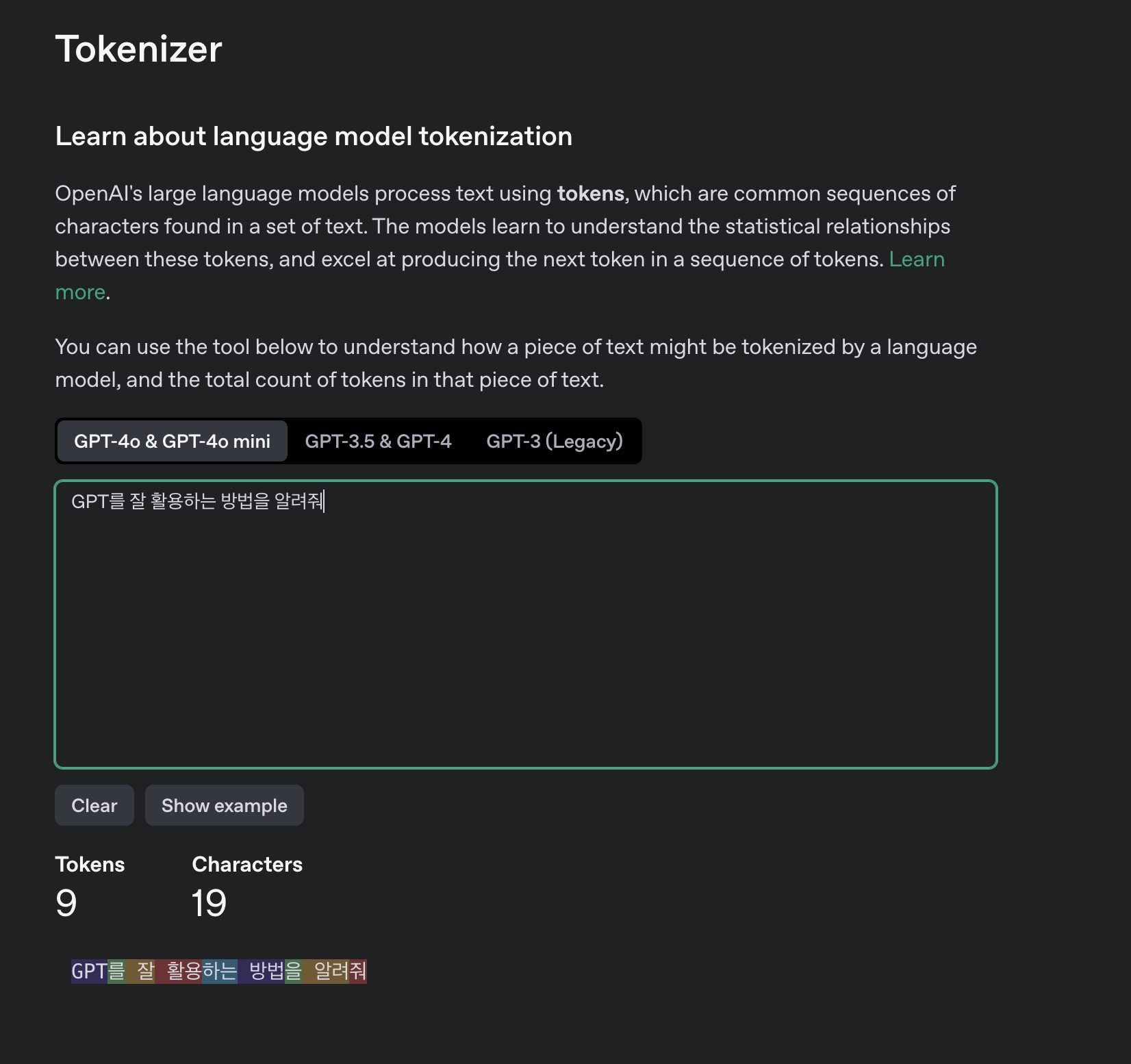
2. Token 계산해보기
GPT API의 요금을 확인해보면 token 단위로 작성되어있다. 글자수가 아니라 token 단위라서 프로젝트에서 실제로 사용해보면서 요금을 뒤늦게 계산했었다.
token = 언어 모델이 이해하고 생성하는 단위

그런데 Open AI 사이트에 token을 계산할 수 있는 tokenizer가 있었다!!
이걸 이용하면 프롬프트를 짠 뒤에 토큰을 계산해보고 이에따른 예상비용을 계산해볼 수 있다.
3. temperature 설정
지금 자료조사를 하다보니 temperature 설정은 기본인 것 같은데... 나는 프로젝트 당시 temperature 설정을 몰라서 따로 설정하지 않았었다.
- temperature은 쉽게말해서 '모델 출력의 무작위성을 제어하는 값' 이다
- 0~2 범위를 가진다
- 값이 0에 가까울수록 좀 더 사실적인 데이터가 제공됨, 확률 분포가 좁아져서 높은 확률을 가진 단어들이 선택되기때문
- 값이 2에 가까을수록 창의적인 데이터가 제공됨. 확률분포가 평평해져서 단어들이 비슷한 확률로 선택되기때문
- temperature의 기본값은 1
- 각 프로젝트에 적절한 값을 찾아서 세팅하면 됨
추천하는 temperature 값
- 0.7~1.0: 자연스럽고 일관적
- 1.2~1.5: 좀 더 창의적이고 다양한 답변
- 0.3~0.5: 매우 예측 가능한 응답 (단답형, 정보성 응답)
사용 예시
async function generateTextTemp(prompt) {
try {
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [{ role: "user", content: prompt }],
temperature: 0.7, // temperature 세팅
});
} catch (error) {
console.error("Error generating text:", error);
}
}
4. Top-P 샘플링
- 누적 확률 분포 샘플링 기법
- 모델이 생성할 수 있는 후보 단어들을 누적 확률이 P 이하인 범위로 제한하는 방식
- 예를들어 0.8 = 누적 확률이 80%인 A, B, C까지의 값만 사용함
이 값에 대해서는 아직 정확히 이해를 못한 것 같다.. 위에 말한 temperature과 비슷한 듯하면서도 다른 값인 것 같다
async function generateTextWithTopP(prompt) {
try {
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [{ role: "user", content: prompt }],
top_p: 0.8, // Top-P 값을 0.8로 설정
});
} catch (error) {
console.error("Error generating text:", error);
}
}
마무리
GPT API를 쓰면서 사용할 수 있는 파라미터들은 여러개 있는데, 사용하면 좋을만한 파라미터를 잘 세팅해서 사용하면 더 효율적으로 사용할 수 있을 것 같다!
이 외에도 API 비용 최적화도 이야기해보면 좋을 것 같고, RAG도 요즘 공부중이라 다음 포스팅으로 정리해보면 좋을 듯하다~~
진짜 오랜만에 회고가 아닌 블로그 글을 써본 것 같은데 한번 정리를 해두니 편할 것 같다!! 앞으로도 종종 시간내서 써야겠다
끝
'AI > 생성형 AI' 카테고리의 다른 글
| 생성형AI 기반 이력서 자동생성 서비스 개발기 (0) | 2025.05.22 |
|---|---|
| GPT API 효율적으로 사용하기 (2) - 비용 최적화 (2) | 2025.03.27 |